ChatGPTに自分で書いたものを読み込んで自分について学んでもらい、 質問に答えてもらうようなツールを作ってみました。
元ネタ
元ネタはこちら。
ScrapboxからエキスポートしたデータをChatGPTに読ませて色々質問してみよう、というもの。
具体的にはファイルは行ごとにまとめられたJSON形式のファイルになっていて、 記事毎にある程度の量の行毎にベクトル化して保存します。 その際にそれぞれ半分ずつオーバーラップがあるように分けていくことで区切りによる情報漏れを少なくしています。
これを全ての記事に対して行った後、質問をベクトル化し、ベクトルの類似度を使って似ている文章を選び出して いくつかをChatGPTに読ませ、その上で質問に答えてもらう、というもの。
Scrapboxのデータを利用していますが、やっていることとしては自分で書いたものを記事ごと、行毎に分けて それをデータ化しているだけなので、 同じようにテキストでもMarkdownでも書いたものを行毎に読み込ませるようにしてあげれば同じようなことができるだろう、と。
text_chatgpt_connector
ということで作ったのがこちら。
Python製で
1
| |
として入れればtccというコマンドが使えるようになります。
Python3.8~Python3.11で動きます。
機能は
tcc index -i <input_dir>:- input_dirは
.txt,.md,.markdownといった拡張子を持ったメモの入ったディレクトリ。ディレクトリ内の全ての該当するファイルをデータ化。 - この拡張子は
-s text,mdといった感じで-sオプションにカンマ区切りで渡すことで変更可能。 -o <index.pickle>で出力先のファイルの指定。デフォルトではカレントディレクトリにindex.pickleというファイルを作る。- 複数のディレクトリを与えたい場合には
-iへ与える値を変えて繰り返し実行。index.pickleは上書きされるのではなくデータが追加されていく。
- input_dirは
tcc ask -q <question>:questionの内容をChatGPTに聞く。- データを作る際に
-oを指定していたり別のディレクトリで作業する場合には作ったデータファイルを-o <index.pickle>で指定。 -nオプションを与えると入力なしで直接質問を聞く。
といったことができます。
入力ファイルの処理
text_chatgpt_connectorでは現状ではほとんど入力ファイルの内容を処理せずにそのまま行毎に分解してデータを作っています。
やっていることは
- URL(
http...)をURLと置き換える(--remain_urlオプションを与えるとそのまま残す) - 空白が続く場合には1文字に置き換える(
--keep_spacesオプションでそのまま残す)
くらいです。
Markdownとかだと色々と記号が入っているので単純な文章入力以外のノイズ的なものも入ってしまいますが、
その辺はそれも含めて学習するものだと思ってやるか、
もしくは別途入力ファイルを処理するような作業を行ってからtccに与えるようにしたりなど
色々考えられるかと思います。
下でやってる今回のテストはブログ用のMarkdownファイルをそのまま突っ込んでいます。
Markdownだとしてもそこそこちゃんと文章を読み込んでくれている雰囲気はありました。
OpenAI API Key
これを使うためにはOpenAIのAPIのKeyが必要です。
OpenAI APIにアカウントを作ったら下からAPI Keyを取得することが可能です。
APIは課金していない状態でも使えて、最初に$18分のお試しクレジットがもらえるのでそれで色々試してみることができます。
ちなみに私は昨年12月頃に登録したようなんですが、確認したら$18分のクレジットが4月1日までになっていたのでちょっと使い切れるくらいとりあえず色々やってみよう、と。
ChatGPTで使われているgpt-3.5-turboを使うAPIは結構安いので$18あればかなりいろいろ試せるかと思います。
超えるまではクレジットカードの登録などもせずに使えるのは良心的。 ただしすでに無料で使っている分だとレートリミットが低かったりする点もあります。
というわけで、Keyを取得したら、.bashrcや.zshrcなどに
1
| |
と書いて環境変数として登録してください。
もしくは、tcc -k <openai_api_key>と-kオプションに直接渡してもできます。
OpenAI APIの利用
OpenAIのAPIはテキストをベクトル化(embed)する際とChatGPTに質問する際に使います。
indexの際にはembedするだけですが、各記事を数行ごとに複数に分けて渡すので
例えばこのブログの各記事くらいの長さだと
記事数の10倍程度の回数を呼ぶ感じになります。
askの際には質問をembedする際に1回、ChatGPTへの問い合わせて1回使うだけです。
なので、indexを作る際には少しお金がかかりますが、質問する際にはほとんどかかりません。
embedするために使う埋め込みモデルにはtext-embedding-ada-002がデフォルトです。(--embeddingオプションで指定可能)。
問い合わせにはChatGPT(3.5)のgpt-3.5-turboを使います。(--chat_modelで変更可能。gpt-4とか使える人はそれを指定してもOK。)
実際にかかった時間や料金
今回はこのブログの記事を読み込ませてみました。
このブログはOctopressというフレームワークを使っていますが、Markdownで書いたファイルを 静的サイトとして変換しています。
各記事は記事毎にファイルに分かれているのでそれらを全部読みます。 記事ファイルにはヘッダーやらサイドバーなどは含まれていません。
ちょうどこのブログも10周年を迎えたので10年分の記事全部をデータ化してみます。

- 記事数: 1,187
- 行数: 223,996
- 単語数: 372,897
- 文字数: 9831,489
- データ量: 12MB
ただし、行数、単語数、文字数はwcの結果。(日本語含みますが、日本語における文字数ではない。)
これらは年ごとにディレクトリに分かれて日付の名前で保存されているのですが、
これを年ごとにtccに与えてデータを作ってみました。
総作成時間は
- 6時間程度
- 1記事20秒程度
- Index数: 12,251
- pickleサイズ: 180MB
となっています。 実際にはAPIのレートリミットにひっかかって待つことも結構あって 実際には1記事15秒位でできていた感じだと思います。
この辺、リミットが上がっている人の場合は ここにもあるように途中にあるsleepを消して行ったり、複数並列でリクエストしたりすることでもっと早くすることも可能かもしれません。
出来上がったデータファイルが結構大きいのでこれを読み込む際にちょっと時間がかかります。 この辺はDB化したりデータの形そのものを工夫したり出来る部分は まだいくらでもありそうなのでもっと本格的にやりたい場合にはちょっと考えたいところ。
かかった料金は
- $2.6 (~340円)
ということで1000記事程度であれば十分$18の範囲でできました。
試してみる
まずは入力無し(-n)で:
1 2 3 4 5 | |
なんか分かってくれた。 ちなみにWeb版で試すと全く知らないという。
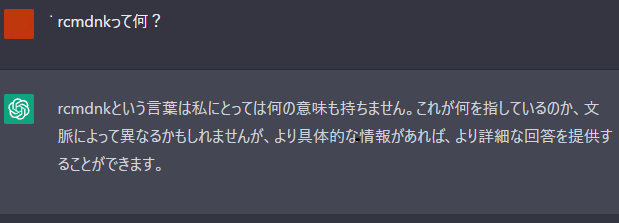
1
| |
何度か聞くと別の人物の名前とかを出されたり。。。
これを作成したデータを読み込ませて見てみると、
1 2 3 4 5 | |
まず、下にあるrefはこの質問時に与えたテキストが含まれていたファイルです。
見てわかる通りほんの一部のファイル(の中の一部のテキスト)を渡しているだけなのでブログ全てを学習している、というわけではありません。 ただ、質問の内容にできるだけ関係ありそうな文章を選んで送っています1
で、肝心の回答ですが、何故か英語にで返されていて、テキストの書き手だ、ということで正しいわけですが、うーむ。 そもそもブログの記事の中に自分のユーザー名が何なのか、とかの説明をしているわけでもないので、この名前についてどうこう聞くのはあまりうまくいかない可能性もあります。
ちょっとうまくいった感じのものだと
1 2 3 4 5 | |
こんなの。これも何故か英語で返ってきてますが。
何も与えないと
1 2 3 4 5 6 | |
こんな感じで全く何もしらないので一応ちゃんと学習できてる感じはします。
ちょっと別角度で、
1 2 3 4 5 | |
こんなの。入力なしだとちゃんと?一般的な感じの返答です。 これが、
1 2 3 4 5 | |
こうなります。以下のような記事を参照しているみたいです。


KeyRemap4MacBookとかは(現在のKarabiner-Element)古い方の記事で新しいのを認識してくれてませんが、 この辺は現在の入力だと時系列などの情報を入れてないこともあるかと思います。 プロンプトを調整して各テキストの日時を入れて、最新の方を重要視するように、的なことを命令すれば Karabiner-Elementの記事を出してくれる可能性があります。
まあこんな感じで質問の内容によっては結構いい感じにブログに沿った答えをだしてくれたりもしますし、 質問するだけならただみたいなものなので色々試せて面白いです。
まとめ
OpenAIのChatGPT関連のAPIを使って遊んでみました。
データ作成にはちょっと時間がかかりましたが、1000記事ほどをデータ化するのにも数百円程度で出来ます。
今回は特に入力ファイルの処理をしてませんが、マックアップに当たる部分を削除したりしてできるだけ文章を抜き出すようにしてあげるだけでももっと精度が良くなるかもしれません。
その他いろいろな議論が Scrapbox ChatGPT Connector - 井戸端 にあるので見てみたり。
本当はEvernoteにあるメモを全部突っ込んで試してみたかったりしますが、 数が多い上に処理が面倒なのと、思いっきり個人情報なものも含まれるので流石にサーバーにアップロードする方法だと出来ないですが、 過去に埋蔵した知識を有効活用するのにこの辺うまく使ってみたいですね。
-
ちなみに
-Vを与えることでverboseモードになり、与えたプロンプトなどを見ることができます。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
$ tcc ask -V -q "rcmdnkって何?" 100%| 12251/12251 [00:00<00:00, 17960.82it/s] PROMPT: Read the following text and answer the question. Your reply should be shorter than 250 characters. ## Text ## Whois情報のチェック お名前.comで設定した **Whois情報公開代行**の設定がきちんと出来てるか一応チェック。 [InterNIC Whois](URL とかでチェックしてrcmdnk.comの情報が正しく代行されてるかチェック。 Domain Name: RCMDNK.COM Registrar: GMO INTERNET, INC. DBA ONAMAE.COM みたいになってれば大丈夫。 ## その他やったこと * Google Search Console(ウェブマスター)で`URL * さらに[アドレス変更ツールの使用 - Search Console ヘルプ](URL * Google Analyticsの`URL * プロパティ設定からデフォルトのURLを`rcmdnk.com`。 * Search Consoleの調整、からSearch Consoleも`rcmdnk.com`のものに。 * Googleアドセンスで`rcmdnk.com`を**設定**<i class="fa fa-arrow-right"></i>** 自分のサイト**で追加。 * Amazonアソシエイトに新しいドメインの追加を連絡。 * 一時的に登録前に新しいドメインに載せてしまうことになりますが、変更前に連絡したら公開されてないサイトだと判断しようがない、ということで、 ド メイン変更とかこういった場合は仕方ないので取り敢えず変更してから連絡してくれれば良い、とのことでした。 ## rcmdnkについて 最後に、GitHubとかでも使ってる`rcmdnk`というユーザー名について、 一応自分なりには意味あるものなんですが、子音ばっかで読みにくくてどうかな、とちょっと思ってたり、 この`rcmdnk_cli`は自動でできたファイルですが、こんな内容 {% codeblock rcmdnk_cli lang:python %} #!/usr/local/opt/python@2/bin/python2.7 # -*- coding: utf-8 -*- import re import sys from rcmdnk_package.cli import main if __name__ == '__main__': sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0]) sys.exit(main()) {% endcodeblock %} ### 設定ファイル: pyproject.toml 直接書く必要があるものとしては 最初の [tool.poetry] name = "rcmdnk-package" version = "0.1.0" description = "" authors = ["rcmdnk <[email protected]>"] の項目にある`description`位。 GitHubのユーザー名とかから保管されていなければ(もしくは違うものを使いたければ)`authors`も。 加えて repository = "URL homepage = "URL readme = "READDME.md" license = "Apache-2.0" keywords = [...] などを定義しておくと良いです。 `readme`はデフォルトでは`README.rst`でSphinx使うreStructuredText形式です。 {% post_card /blog/2016/05/01/computer-brew-file-github/ Read the Docs(Sphinx)でオープンソースのドキュメントをいい感じに書いてみる %} 変更したければ`readme`の設定で`md`にしても変換して PyPIのページで表示してくれます。 `license`は[SPDX License List](URL にあるIdentifierを指定するとパッケージに自動で含めてくれま す。 後は`version`を必要に応じて更新していきます。 (その際、**src/rcmdnk_package/__init__.py**や**tests/test_rcmdnk_package.py**などにある Pull Requestを出してみましたが、更新が古いプラグインで反応がまだ無いですが、 [rcmdnk/yankround.vim](URL に変更したものがあります。 Deinとかであれば、 call dein#add('rcmdnk/yankround.vim') で導入できます。 ## まとめ YankshareはYankshareで別物のクリップボードになるのでこれはこれで 特別に取っておきたいものとかに使えると は思います。 レジスターとかを使えば良い、という点もあるかもしれませんが余り上手く使いこなせてないので ちょっと整理してみる必要はあるかもしれません。 いずれにしろYankroundのアップデートで統一してクリップボードを共有 して 履歴管理できる様になり結構便利になりました。 rcmdnk版: {% githubrepo rcmdnk/vim-markdown %} ### Folding よりシンプルに高速に。 本家では**python-mode**という別の方法に出来たり しますがrcmdnk版ではその様な設定もありません。 根本的にやり方が別物になっていますが、 出来ることは大体同じで、加えてLiquid(Jekyll)のタグなどにも対応しています。 本家の方では行の内容を見て 解析していますが こちらでは付けたシンタックスハイライトの内容を主に見ていて その分シンプルなコードに出来、有効にしても大分高速になっています。 ### Text emphasis on multi-lines `**太字**`みたいにして**太字**にしたりする場合、 ```vim let g:vim_markdown_emphasis_multiline = 1 ``` の値が1だと複数行でも続けて強調、0だと同じ行内に閉じる`**`がなければ 強調しない、という設定が出来ます。 本家では初期値が1なんですが、これだと文中に`_`とか`*`とかある場合に 次にそれが出てくるまで延々と強調を続けます。 これが結構面倒で複数行に渡って強調する 必要があることはあまりないし、 したければ一行にまとめるか、 複数行ならその行毎に強調を当てれば出来るので初期値を0にしてあります。 まあ設定で出来ることなのでどちらでも良いのですが自分用に。 sentakuで急に増えてるのはredditにさらしてみた際の現象。 (その割には大したことない反応ですが。。。) {% post_card /blog/2014/02/23/computer-bash-zsh/ redditにスクリプトを晒してみた %} [Utility to make sentaku (selection, 選択(sentaku)) window with shell command. : commandline](URL ここ最近WindowsのどこでもVimをエミュレー トする[vim_ahk](URL 同じ様なことをMacでやる[rcmdnk/KE-complex_modifications](URL の方は余り反応がなくて寂し いところですが。Forkじゃなくてちゃんと名前をつけた別レポジトリにしたほうが良いのかも。 と、そんな感じで自分でも楽しめますし、 今流行りのレポジトリのスターの増加の様子を見ると流行り廃りがなんとなくわかるかもしれませ ん。 ちなみに3000を超えるスターをもつレポジトリから情報を取るにはAPIのアクセスリミットを超えてしまうため GitHubのアカウントが必要で、ユーザー名/パスワードを使用するかアクセストークンを入れる様求められます。 2段階認 証をしているとユーザー名ではだめなのでアクセストークンを取得して入れる必要があります。 ([New personal access token](URL tokensに関するScopeな何も選択しないまま作ったものでOK。) ただ、10万スターを超える様な{% fnin %}[Search · stars:>1](URL endfnin %} これが今は`rcmdnk - OneNote`みたいにユーザー名を含むようなタイトルになっていました。 > [doesn't seem to work on onenote on windows 10 · Issue #37 · rcmdnk/vim_ahk](URL これによってOneNote上ではデフォルトでは有効に ならないような状態でした。 勿論、自分でタイトルを調べて`Settings`でそのタイトルを入れれば有効になるのですが、 上のような`SetTitleMatchMode`の設定があったので導入してみました。 これで、例えばブラウザとかで特定のページに関して、とかもやりやすくなるかもしれません。 ## AutoHotkeyの色々 今まで書いたものとかについては以下か ら。 {% post_card /blog/tags/autohotkey/ Tag: AutoHotkey %} ちなみに今使っているのはAutoHotkey_Lのバージョン1の方です。 使っている今のバージョンはVersion 1.1.31.00。 > [AutoHotkey](URL > [Lexikos/AutoHotkey_L: AutoHotkey - macro-creation and automation-oriented scripting utility for Windows.](URL ドキュメントを見るとV2の方もかなりできてる様ですが、根本的な言語体制が変わってる感じになってるので 移行するとしたら結構1から書き直さないといけない部分も出てくるかもしれません。 今回変更した中で色々調べたりもしたので気になった点とかをまとめておきます。 ### 関数 > [Functions - Definition & Usage AutoHotkey](URL ## rcmdnk-color.vim ということで`ron`をわざわざ使う必要は無い、という結論。 だったら上の設定をプラグインとしてまとめて 後々変えたい所をプラグインとしてカラースキーム設定して行こう、ということになりました。 {% githubrepo rcmdnk/rcmdnk-color.vim %} 特に特別なものでもないのでcolorschemeの名前も`rcmdnk`です。 プラグイン名 もそれにしてしまうとちょっとあれなので`rcmdnk-color.vim`に。 プラグインの作り方は**colors**というディレクトリを作ってそこにカラースキーマファイルを作るだけ。 これでdein.vimなどで {% codeblock lang:vim %} if dein#load_state(s:dein_dir) call dein#begin(s:dein_dir) ... call dein#add('rcmdnk/rcmdnk-color.vim') ... call dein#end() call dein#save_state() endif ... if dein#tap('rcmdnk-color.vim') colorscheme rcmdnk endif {% endcodeblock %} とかやれば導入できます。 中身は今回は簡単なものを作るのでデフォルトのスキーマを参考に。 > [vim/runtime/colors](URL まず最初に {% codeblock rcmdnk.vim lang:vim %} set background=dark hi clear if exists('syntax_on') syntax reset endif let g:colors_name = expand('<sfile>:t:r') {% endcodeblock lang:vim %} みたい なのが大体どのカラースキームでも共通で必要なことです。 変えるとしたら最初の`background`。 暗いテーマなら`dark`、明るいテーマなら`light`。 > [新しいrcmdnkのSyntax](/rawhtml/vim-markdown/rcmdnk-vim-markdown-20141030.html) スペルチェックの所は手元 のターミナルでは下線が付いてるんですが、 `:TOHtml`ではなぜかこれだけ反映されずに付いてません。。。 (ターミナルでやる限りは上手く行ってます。) 今回のアップデートでは * YAMLブロックの部分をハイライト出来る様になった ことと * Octopressのコードブロックでファイル名だけで反映できる様になった所 が特に嬉しいところです。 プラ グインのアップデートが上手くいかない場合はこちらを参照: > [VimでNeoBundleのアップデートに伴いプラグインのデフォルトブランチをmasterに変更](/blog/2014/10/27/computer-vim-markdown/) ## Question rcmdnkって何? THINKING... RESPONSE: { "choices": [ { "finish_reason": "stop", "index": 0, "message": { "content": "rcmdnk is a username used by the author of the text.", "role": "assistant" } } ], "created": 16XXXXXXXX, "id": "chatcmpl-XXXXXXXXXXXXXXXXXXXXXXXXXXXXX", "model": "gpt-3.5-turbo-0301", "object": "chat.completion", "usage": { "completion_tokens": 15, "prompt_tokens": 3640, "total_tokens": 3655 } } ANSWER: >>>> rcmdnkって何? > rcmdnk is a username used by the author of the text. ref. 2017-01-01-blog-octopress.md, 2019-02-04-computer-python.md, 2018-10-01-computer-vim.md, 2017-07-01-computer-vim-markdown.md, 2019-03-06-computer-github.md, 2020-02-03-computer-windows-autohotkey.md, 2017-11-13-computer-vim.md, 2014-10-30-computer-vim-markdown.md