
コンピューター上で複数バイトを使うデータを記憶する時に どのような順序で置いておくか、と言う配置の方法をエンディアン(endianness、バイト順)と言います。
普段プログラムをするときなんかは殆ど気にすることはありませんが、 この配置方法は場合によって違うことがあり、バイト単位で自分で色々 データを管理するような時にはきちんと配慮する必要があります。
とは言っても殆ど気にする時は無いんですが、 久々にちょっと気になって チェックする方法とか についてちょっと見なおしたのでその辺のメモ。
ビッグエンディアンとリトルエンディアン
プログラムを動かすときに、データは1バイト単位(=8ビット)で 記憶されていきます。
それぞれにアドレスが割り振られて、このアドレスに使える数の制限が 32bit(2^32bit ~ 4GB)マシンとか64bit(2^64bit ~ 16EB)マシンとかで変わってきます。
2バイト以上のデータを保存する時に、どのような順序で記憶していくか、 という方法を示すのがエンディアンになります 1。
主にビッグエンディアンとリトルエンディアンの二種類があって、 ビッグエンディアンの方はデータの上の方から準に詰めていくのに対し、 リトルエンディアンは下の方から順に詰めていきます。
12 34 56 78
みたいな4バイトのデータの固まり(16進法で8桁、2桁ごとが1バイト)が有る時に、
一番最初のメモリに入るのが
12なのか78なのか、と言う感じ。
インテルのCPUはリトルエンディアンで、 一方モトローラのはビッグエンディアンで、 しばしばIntel v.s. Motorola的な対応の見せ方を見ることもあります 2。
今は普通のパソコンはMacですらインテルのCPUが殆どなので 大概のものはリトルエンディアンになってます。
ちょっと前までMacで使われてたPowerPCは 両方使えるバイエンディアンというものでしたが、 普通にMacで使う際にはビッグエンディアンとして動いていました。
なので、昔はWindowsマシンはリトルエンディアンで Macはビッグエンディアン、みたいな感じもあって、 Macの特徴、的な所でちょちょっとしたデモンストレーションをやって データがその順通りに表示される、的な事をやって見せてもらったりしたことがあったな、と。
チェック方法
C++を使ったチェック方法
1 2 3 4 5 6 7 8 9 10 11 12 | |
こんな感じのC++のコードを用意します。
ここでint型は4バイトだとします。
4バイトなので16進数で8桁の数を最初に入れてあります。
これを1バイトのunsigned charに1バイトずつ入れた形です。
これを実行すると、ビッグエンディアンな環境では
$ ./endiancheck1
12 34 56 78
と表示され、リトルエンディアンな環境では
$ ./endiancheck1
78 56 34 12
となるはずです。
もうちょっと色々なサイズとかを見てみようと思うとこんな感じ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
これを実行するとビッグエンディアンな環境では
$ ./endiancheck2
8 bytes: 123456789abcdef0
4 bytes: 12345678 9abcdef0
2 bytes: 1234 5678 9abc def0
1 byte : 12 34 56 78 9a bc de f0
と表示され、リトルエンディアンな環境では
$ ./endiancheck2
8 bytes: 123456789abcdef0
4 bytes: 9abcdef0 12345678
2 bytes: def0 9abc 5678 1234
1 byte : f0 de bc 9a 78 56 34 12
となります。
コードについてちょっと補足しておくと:
- union(共用体)はメンバが全て同じメモリを共有する構造。
一番大きなメンバの文だけメモリが確保される。
上の例では全て8バイトなので全てが同じ4バイト分のメモリを共有してる。
- なので最初に
b8に値を入れた時点で他のメンバもこの値を参照する。
- なので最初に
std::hexをstd::coutに与えることで、以降数値を16進法で表示するようになる。unsigned char型はそのままcoutすると対応するアスキーコードを表示しようとするので ここではintにキャスト。printfを使って数値としてフォーマットを指定する時は キャストせずにそのままでも数値として表示できる。charだけunsignedが必要。これはcharをcastする際、char型だと1ビット分が符号に使われるため、0x80以上の数値をintとかに変換しようとすると、上から借りてくる形になってしまって、0xffffff80になってしまうため。
図にするとこんな感じ。
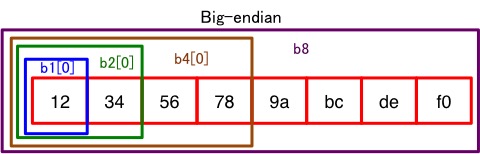
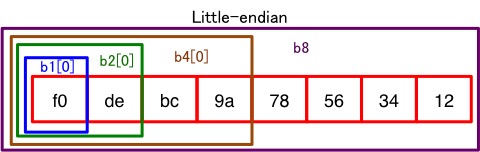
一番左がメモリ上のアドレスの小さい位置になります。
コマンドラインでodを使った方法
odコマンドは入力を指定された形で出力してくれるコマンドで、
文字列を文字コードに変換したり出来ます。
これを使って
$ echo -n "12345" | od -t x
というコマンドを打ってみます。
od -t xで16進法で入力の格文字を表示します。
それぞれの文字コードは16進法で
| 文字 | コード |
|---|---|
| 1 | 31 |
| 2 | 32 |
| 3 | 33 |
| 4 | 34 |
| 5 | 35 |
となってます3。
実行してみるとビッグエンディアンな環境では
$ echo -n "12345" | od -t x
0000000 31323334 35000000
0000005
と表示され、リトルエンディアンな環境では
$ echo -n "12345" | od -t x
0000000 34333231 00000035
0000005
一番左の数字はそれぞれの行の先頭が何バイト目か、というのを示している数値です。 2行目が5になってるのは一行目に5つの文字列が含まれてるためです 4。
odではデフォルトで4バイト毎に区切られて表示される様になっているので、
上の様に8桁の数字毎に書かれていますが、
これを元の数値の文字列に直せばそれぞれ、
1234 5
と
4321 5
となってる事になります。
ここでもリトルエンディアンな環境では逆さになってることが確認できます。
Python
Pythonにはsysモジュールの中にあるbyteorderという変数に
エンディアンがどちらか、の情報が入る様になっています
5。
ビッグエンディアンなら
$ python
>>> import sys
>>> print sys.byteorder
big
>>>
リトルエンディアンなら
$ python
>>> import sys
>>> print sys.byteorder
little
>>>
と表示してくれます。
Ruby
Rubyには配列を1つのバイナリデータにしたり、
1つのバイナリデータを決まったバイト数毎の配列に変換したりする、
pack、unpackというメソッドがあります
6。
これを使うと、 ビッグエンディアンでは
$ irb
irb(main):001:0> [1,2].pack("s2")
=> "\x00\x01\x00\x02"
irb(main):002:0>
リトルエンディアンでは
$ irb
irb(main):001:0> [1,2].pack("s2")
=> "\x01\x00\x02\x00"
irb(main):002:0>
となります。
packでの引数はs2となってますが、
このsはshort型の大きさとして(ここでは2バイト)配列を結合する、
ということを意味します。
その後の数字はいくつ分を結合するか、を意味していて、この場合は
配列の中身の個数分2個を繋げる、と言う意味です。
(全部であれば数字の代わりに*を使っても同じ。)
それぞれ2バイトの大きさとして見るため、0x1を2バイトに置く時に、
0x0001をどう置くか、と言う部分で両者で違ってきます。
リトルエンディアンの方では上下のバイト分が1と2の時それぞれで逆転して
配置されています。